作者:王子饼干 ——镇江虹视游戏科技有限公司联合创始人、《多洛可小镇》制作人
原文链接:UnityShader入门精要笔记20:渲染优化技术
原文发布时间:2020年9月7日
文章类型: 授权转载
不登高山,不知天之高也;不临深溪,不知地之厚也。——荀子《劝学》
笔记当前使用的Unity版本:“2019.3.3”
笔记当前Unity最新发行版:“2019.3.7”
¶ 1.概述
优化一直是游戏开发领域必不可少的一个部分,尤其是在和实时渲染密切相关的着色器部分。在Unity当中,提供了类似于批处理和LOD(Level of Detail)技术等。本章节来了解一下这些内容。
¶ 2.影响性能的主要因素
对于游戏来说,我们无非是主要控制两类资源,GPU和CPU,其中GPU负责分辨率相关的处理,而CPU负责帧率相关的处理。据此,造成性能瓶颈的理由大概可以分以下几点。
¶ 2.1 CPU
- 过多的DrawCall
- 复杂的脚本或者物理模拟
¶ 2.2 GPU
顶点处理相关
- 过多的顶点
- 过多的逐顶点计算
片元处理相关
- 过多的片元
- 过多的逐片元计算
¶ 2.3 带宽
- 使用了尺寸很大且未压缩的纹理
- 分辨率过高的帧缓存
对于CPU来说,限制它的主要是每一帧中drawcall的数目。drawcall就是在每次绘制之前,CPU给GPU的一个命令,虽然只是一个简单的命令,但是它也会包含很多程序,因而如果我们有A模型和B模型,渲染A的时候调用一次drawcall,渲染B的时候也调用一次drawcall会比调用一次drawcall渲染AB两个模型更加耗费性能。因而我们希望尽量在一次drawcall中渲染更多的模型。
针对CPU的优化,Unity提出了批处理技术来优化drawcall的数目,针对GPU的优化,主要有三种不同的策略,一种是减少模型的顶点,针对减少模型的顶点,我们有这几种方法
- 优化几何体
- 使用模型的LOD(Level of detail)技术
- 使用遮挡剔除技术
一种是减少需要处理的片元的数量,针对减少片元,有这几种方法
- 控制绘制顺序
- 警惕透明物体
- 减少实时光照
一种是减少计算的复杂度,针对减少计算的复杂度,有这几种方法
- 使用Shader的LOD技术
- 代码方面的优化
针对带宽的优化,则主要是减少纹理的大小并且利用分辨率进行纹理的缩放。
¶ 3.Unity中的渲染分析技术
Unity内置了一些工具,来帮助我们方便的查看和渲染相关的各类统计数据。在Unity5中,这些工具包括渲染统计窗口(Rendering Statistics Window)、性能分析器(Profiler)以及帧调试器(Frame Debugger)需要注意的是,在不同的平台上,这些工具中显示的数据也会发生变化。
¶ 3.1 渲染统计窗口
渲染统计窗口是Unity5中加入的功能,我们可以通过在Game视图的右上方的菜单中单机Stats按钮来打开它。
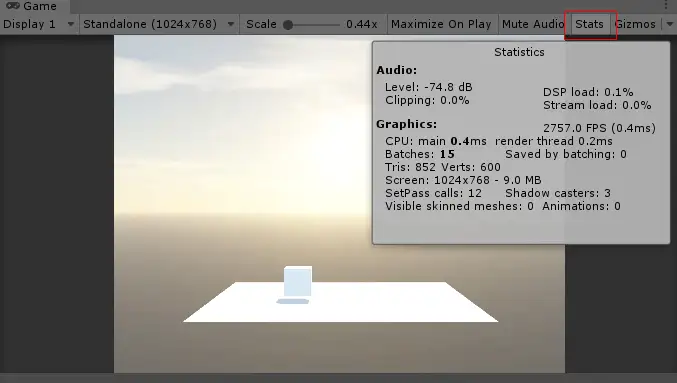
渲染统计窗口主要包含了三类信息,包括音频,图形和网络。有非常多的重要数据,如下所示
- 每帧的时间和FPS
- Batches:一帧当中所需要处理的批数量
- Saved by batching:合并处理的批数目,这个数字表明了批处理为我们节省了多少drawcall
- Tris和Verts:需要绘制的三角面片和顶点的数目
- Screen:屏幕的大小,以及它占用的内容大小
- SetPass:渲染使用的pass的数目,每个pass都需要Unity的runtime来绑定一个新的Shader,这可能造成CPU的瓶颈
- Visible Skinned Meshes:渲染的蒙皮网格的数目
- Animations:播放的动画数目
不过在Unity5中,渲染统计窗口已经不再显示drawcall数目,如果希望查看类似于drawcall和其他更为详细的数目,可以通过Unity编辑器的性能分析器来查看。
¶ 3.2 性能分析器
我们可以通过WIndow->Analysis->Profiler来打开性能分析器,性能分析器中的渲染区域,提供了更多关于渲染统计信息,它分为几个不同的板块,包括CPU的使用,内存使用,渲染,UI,网络,物理引擎等。不过总的来说,如果我们希望细致的对每一个drawcall的内容进行分析,需要借助帧调试器来帮忙。
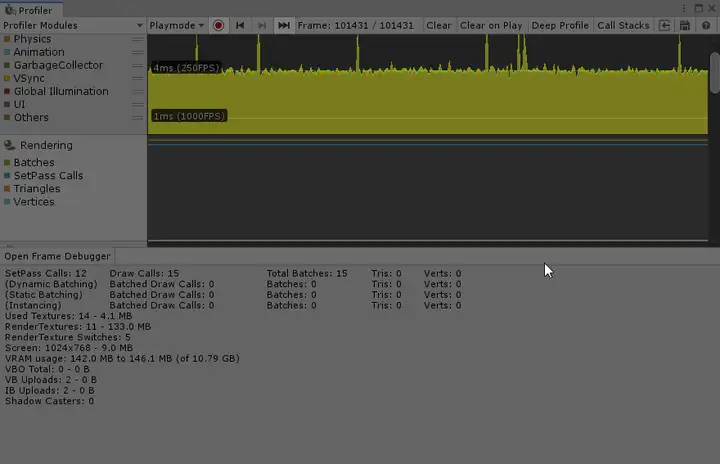
¶ 3.3 帧调试器
帧调试器可以通过Window->Analysis->Frame Debugger来打开,帧调试器可以让我们看到每一个drawcall是如何绘制的,并且我们可以看到我们所编写的着色器的很多参数具体信息。
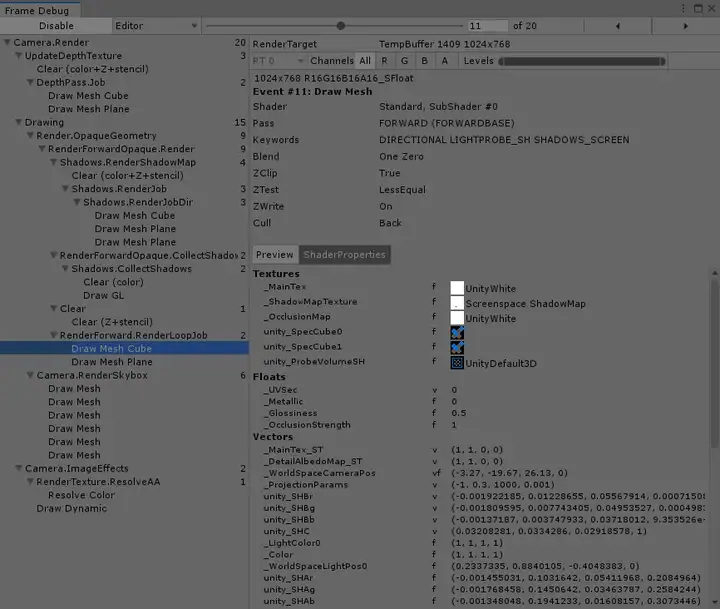
比如可以通过下面的参数来了解使用Unity3d自带的标准着色器来绘制一个Cube的参数信息。
¶ 3.4 其他的渲染分析工具
除了Unity自带的渲染工具,还有非常多的好用的工具,比如RenderDoc等,不过这些内容并非当前的核心,所以后面会写新的博客来说。
¶ 4.减少DrawCall的数目
最常见的技术就是批处理了,举个最简单的例子来说,在A地有一片林场,在B地需要木头进行建筑施工,于是在A地砍树,并运送到B地。假设卡车从A地跑到B地(相当于调用了一次drawcall),只运送了一根木头,那么这个进程就会很慢。所以卡车一次最好多运送几根木头,这样就可以有效的提高效率了,这就是批处理。
批处理的核心思想就是尽可能多的在一个drawcall里面绘制多个模型。
什么样的物体可以一起处理呢,答案就是使用同一个材质的物体,对于使用同一个材质的物体,它们唯一的不同就是顶点的不同,于是我们可以把两个模型合并在一起,变成一个模型。这样,一起交给GPU去绘制,就相当于只绘制了一个模型。Unity提供了两种批处理的方式,一种是动态批处理,一种是静态批处理,动态批处理的好处是它是全自动的,不需要我们自己去控制的,而且渲染出来的物体可以移动,不过缺点就是限制比较大。很容易破坏批处理的机制。静态批处理的有点就是自由度很高,限制比较少,但缺点就是不能动,被锁定,通常是用于一些无法交互的场景。
¶ 4.1 动态批处理
动态批处理就是找到所有的使用同一个材质的物体,把它们的模型合并在一起,成为一个新的模型,然后交给GPU去绘制,它是可以运动的,因为每次绘制之前,Unity都会合并一次网格。虽然我们不需要自己控制动态批处理,但是需要了解什么样的条件才可以达到动态批处理。
- 能够进行动态批处理的网格顶点属性规模要小于900,例如,如果Shader中需要使用顶点位置,法线和纹理坐标这3个顶点属性,那么想要模型能够被动态批处理,它的顶点数目不能超过300。需要注意的是,这个数字在未来可能会发生变化。因此不要依赖当前给出的数据。
- 一般来说,所有的对象都需要使用同一个缩放尺度,不过Unity5中已经去掉了这种限制
- 使用光照纹理(LightMap)的物体需要小心处理,这些物体需要额外的渲染参数,例如,在光照纹理上的索引,偏移量和缩放信息等。因此,为了让这些物体可以被动态批处理,我们需要保证它们指向光照纹理中的同一个位置。
- 多Pass的Shader会中断批处理。在前向渲染中,我们有时需要使用额外的Pass来为模型添加更多的光照效果。但这样一来模型就不会被动态批处理了。
相对来说,动态批处理是很难达成的,比如有多个点光源,或者平行光开启了阴影都可能会导致动态批处理的失效。
¶ 4.2 静态批处理
Unity提供了另外一种批处理方式,即静态批处理。相对于动态批处理来说,静态批处理适用于任何大小的几何模型。它的实现原理是,只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格当中,这意味着模型没有办法在移动了。不过由于其只合并一次,所以它的效率更高,不过它往往需要占用更多的内存。这是由于,如果在静态批处理前一些物体共享了相同的网格,那么在内存中每一个物体的都会对应一个该物体的复制品,即一个网格会变成多个网格发送给GPU。如果这类使用同一网格的对象很多,那么这就会成为一个性能的瓶颈了。例如,如果一个使用了1000个相同树模型的森林中使用静态批处理,就会多使用1000倍的内存,这会造成严重的内存影响。
静态批处理的实现非常简单,只要我把物体的静态选项勾上就可以了。如下图所示
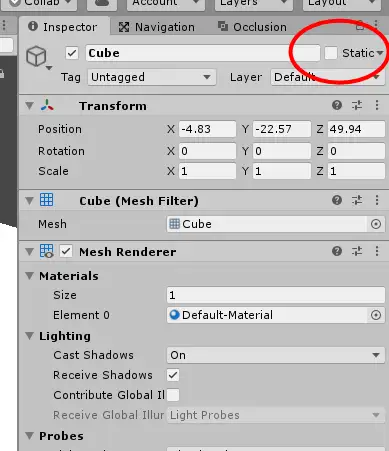
如果场景中包含了除了平行光以外其他的光源,并且在Shader中定义了额外的Pass来处理他们,这些额外的Pass部分是不会被批处理的。
¶ 4.3 共享材质
从之前的内容可以看出,无论是动态批处理还是静态批处理,都要求模型之间需要共享同一个材质。但不同的模型之间总会需要有不同的渲染属性,比如使用不同的纹理,颜色等。这个时候需要一些策略来尽可能的合并材质。
如果两个材质之间只有使用的纹理不同,我们可以把这些纹理合并到一张更大的纹理中。这张更大的纹理被称为一张图集,一旦使用了同一张纹理,我们就可以使用同一个材质,再使用不同的采样坐标即可。
但是只允许纹理不同限制还是非常大的,但是不论是动态批处理还是静态批处理,它们都要求使用同一个材质,是同一个材质,而非同一个着色器。而我们只要调整了材质的参数,它就会影响到所有使用该材质的对象。一种常见的办法就是使用网格的顶点数据(最常见点就是顶点颜色数据)来储存这些参数。
经过批处理后的物体会被处理成更大的VBO发送给GPU,VBO中的数据可以作为输入传递给顶点着色器,因此,我们可以巧妙的对VBO中的数据进行控制,从而达到不同的效果。一个例子是,森林场景中所有的树使用了同一种材质,我们希望他们可以通过批处理来减少drawcall,但不同的树的颜色可能不同。这时,我们可以利用网格的顶点的颜色数据来调整。
需要注意的是,如果希望在C#代码钟对共享材质进行控制,需要使用Renderer.sharedMaterial这个参数,如果我们使用了Renderer.material,那么它会生成一个新的材质。这不是我们希望看到的,因为生产了一个新的材质,和批处理就没有什么关系了。
¶ 4.4 批处理的注意事项
使用批处理有以下几点建议
- 尽可能的选择静态批处理,但是要时刻小心内存的消耗,并且记住经过静态批处理的物体不可以再被移动。
- 如果无法进行静态批处理,而要使用动态批处理的话,那么请小心上面提到的各种条件限制。例如,尽可能的让这样的物体少,并且尽可能让这些物体包含少量的顶点属性和顶点数目。
- 对于游戏中的小道具,比如可以拾取的金币等,可以使用动态批处理。
- 对于包含动画的这类物体,我们无法全部使用静态批处理,但其中如果有不动的部分,可以把这部分标记为“Static”
另外,如果一个Shader中存在一些需要在模型空间进行计算的部分,我们需要取消批处理,否则将会得到错误的结果。
¶ 5.减少需要处理的顶点数目
尽管drawcall是一个重要的性能指标的,但顶点数目同样有可能成为GPU的性能瓶颈。在本节中,我们将给出三个常用的顶点优化策略。
¶ 5.1 优化几何体
从模型的建立开始,我们就需要对模型进行优化,再不让模型产生效果的差异的同时,我们应该尽可能的减少模型中的三角面的数目。
¶ 5.2 模型的LOD技术
另外一个减少模型顶点数目的技术就是lod技术,这种技术的原理是,当一个物体离摄像机很远的时候,模型上的很多细节是无法被观察到的。因此,LOD技术允许当对象远离一个摄像机的时候,减少模型上的面片数量,从而提高性能。
在Unity中,我们可以使用LOD Group组件来为一个物体构建一个LOD。我们需要为同一个对象准备多个包含不同细节程序的模型,然后把它们赋给LOD Group组件中的不同等级,Unity就会自动判断当前位置上需要使用哪个等级的模型。
¶ 5.3 遮挡剔除技术
遮挡剔除技术(Occlusion Culling)技术可以用来消除那些在其他物体后面看不见的五件,这意味着资源不会浪费在计算那些看不到的顶点上,从而提高性能。这需要和视椎体剔除区分开来,视椎体剔除只会剔除那些不在摄像机范围内的物体,而遮挡剔除是剔除在摄像机内,但是被其他的物体遮挡而看不见的物体。遮挡剔除技术会使用一个虚拟的摄像机来遍历场景,从而构建一个潜在可见的对象集合的层级结构。在运行时刻,每个摄像机将会使用这个数据来识别哪些物体是可见的,哪些是不可见的,使用遮挡剔除技术,不仅可以减少处理的顶点数目,还可以减少Overdraw,提高游戏性能。
模型的LOD技术和遮挡剔除技术可以同时减少CPU和GPU的负荷,CPU可以提供更少的drawcall,而GPU需要处理的顶点和片元数目也减少了。
¶ 6.减少需要处理的片元数目
另一个造成GPU瓶颈的部分是需要处理过多的片元,这部分优化的重点在于减少overdraw,简单来说,overdraw指的就是同一个像素被绘制了多次。
Unity提供了查看overdraw的视图,我们可以在Scene视图的左上方的下拉菜单中选中Overdraw即可。实际上,这里的视图只是提供了查看物体相互遮挡的层数,并不是真正的最终屏幕绘制的Overdraw。也就是说,可以理解为它显示的是,如果没有使用任何深度测试和其他优化策略时的Overdraw。这种视图是通过把所有对象都渲染成一个透明的轮廓,通过查看透明颜色的累积程度,来判断物体之间的遮挡。当然,我们可以使用一些措施来防止这种最坏情况的出现。
¶ 6.1 控制绘制的顺序
控制绘制点顺序是一个重要的优化策略,由于深度测试的存在,如果我们可以保证物体都是从前往后绘制的,那么就可以很大程度上减少overdraw。这是因为,在后面绘制的物体由于无法通过深度测试,就不会在进行后面的渲染处理。
在Unity中,那些渲染队列数目小于2500(比如Background,Geometry,AlphaTest)的对象都被认为是不透明(opaque)的物体,这些物体总体上是从前往后绘制的,而使用其他的队列(如“Transparent”“Overlay”等)物体,则是从后往前绘制的。这意味着,我们可以尽可能的把物体的队列设置为不透明的渲染队列,从而尽量避免使用半透明队列。
而且,我们可以充分利用Unity的渲染队列来控制绘制的顺序,例如,在第一人称射击游戏中,对于游戏中的主要人物角色来说,他们使用的Shader往往比较复杂,但是,由于他们通常会挡住屏幕的很大一部分区域,因此我们可以先绘制它们(使用更小的渲染队列)。而对于一些敌方角色,它们通常会出现在各种掩体里面,因此,我们可以在所有常规的不透明物体后面渲染它们。而对于天空盒来说,它几乎覆盖了所有的像素,而且我们知道它永远会出现在所有物体的后面,因此,它的队列可以设置为“Geometry+1”。这样,就可以保证不会因为它而造成overdraw。
这些排序的思想往往可以节省掉很多的渲染时间。
¶ 6.3 减少实时光照和阴影
实时光照对于移动平台来说是一种非常昂贵的操作。如果场景中包含了过多的点光源,并且使用了多个pass的Shader,那么很有可能会造成性能的下降。例如,一个场景里如果包含了3个逐像素的点光源,而且使用了逐像素的Shader,那么很有可能将drawcall的数目(CPU的瓶颈)提高三倍,同时也会增加overdraw(GPU的瓶颈)。这是因为对于逐像素的光源来说,这些被光源照亮的物体需要再被渲染一次。更糟糕的是,无论是静态批处理还是动态批处理,对于这种额外处理逐像素光源的pass都是无效的,也就是说,它会中断批操作。
当然,光源是一个出色的游戏画面必不可少的内容。我们可以提前把光照烘焙到一张光照纹理(lightmap)中,然后在运行时刻,只需要根据纹理采样得到光照结果即可。另一个模拟光源的方法是使用God Ray。场景中很多小型光源的效果都是靠这种方法模拟的,它们一般不是真的光源,很多情况下是通过透明纹理模拟得到的。
在游戏《ShadowGun》中,游戏角色看起来使用了非常复杂高级的光照计算,但这实际上是优化后的结果。开发者们把复杂的光照计算存储到一张查找纹理(lookup texture,也称为查找表,lookup table LUT)中。然后在运行时刻,我们只需要根据光源方向、视角方向、法线方向等参数,对LUT采样得到光照结果即可。使用这样的查找纹理,不仅可以让我们使用更出色的光照模型,例如BRDF模型,还可以利用查找纹理的大小来进一步提升性能,例如,主要角色可以使用更大分辨率的LUT,而一些NPC使用较小分辨率的LUT。《ShadowGun》的开发者开发了一个LUT烘焙工具,来帮助美术人员快速调整模型光照,并把结果存储到LUT中。
同样,实时阴影也是非常消耗计算量的。我们也应该警惕使用。
¶ 7.节省带宽
大量的使用未压缩的纹理,以及使用过大分辨率都会造成由于贷款而引发的性能瓶颈。
¶ 7.1 减少纹理大小
之前提到过,使用纹理图集可以帮助我们减少drawcall的数目,而这些纹理的大小同样是一个需要考虑的问题,需要注意的是,所有纹理的长宽比最好是正方形,而且长宽值最好是2的整数幂,这是因为有很多优化策略只有在这种时候才可以发挥最大的作用。在Unity5中,几遍我们导入的纹理长宽值并不是2的整数幂,Unity也会自动把长款转换为离它最近的2的整数幂值。但我们仍然应该在制作美术资源时就把这条规则谨记。
除此之外,我们还应该尽可能的使用多纪检员纹理技术(Mipmapping)和纹理压缩。在Unity中,我们可以通过纹理导入面板来查看纹理的各个导入属性。通过把纹理类型设置为Advanced,就可以自定义许多选项。例如是否生成多级渐远纹理,当勾选了Generate Mip Maps后,Unity就会为同一张纹理创建出很多不同大小的纹理,构建一个纹理金字塔,根据摄像机与模型的距离来选择目标纹理。除非并没有严格的距离概念,比如GUI或者2D游戏,否则我们都应该生成多级渐远纹理。
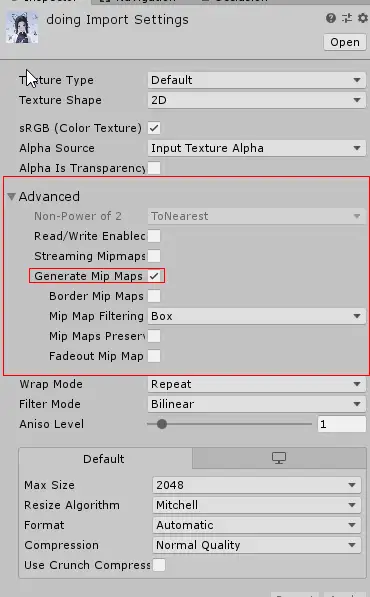
纹理压缩同样可以节省带宽。但对于像Android这样的平台,有很多不同架构的GPU,纹理压缩就变得有点复杂,因为不同的GPU架构有它自己的纹理压缩格式,例如,PowerVRAM,的PVRTC格式,Tegra的DXT格式,Adreno的ATC格式。所幸的是,Unity可以根据不同的设备选择不同的压缩格式,而我们只需要把纹理压缩格式设置为自动压缩即可。但是,GUI类型的纹理同样是个例外,一些由于对画质的要求,我们不希望对这些纹理进行压缩。
¶ 7.2 利用分辨率缩放
过高的屏幕分辨率也是造成性能下降的原因之一,尤其是对很多低端手机,除了分辨率搞其他硬件条件均不尽如人意,而这恰恰是游戏性能的两个瓶颈。过大的屏幕分辨率和糟糕的GPU,因此,我们可能需要对特定机器进行分辨率的放缩。当然,这样可能会造成游戏效果的下降,但性能和画面之间永远是个需要权衡的话题。
¶ 8.减少计算的复杂度
计算复杂度同样会影响游戏的性能。主要通过两类方法来减少计算的复杂度。
¶ 8.1 Shader的LOD技术
Shader的LOD技术和模型的LOD技术是两码事,不过它们很类似就是了。Shader的LOD技术可以控制使用Shader等级,它的原理是,只有Shader的LOD值小于某个设定的值,这个Shader才会被使用,而使用了那些超过设定值的Shader的物体将不会被渲染。
我们通常会用SubShader中使用类似下面的语句来指明该Shader的LOD值。
SubShader{
Tgas{"RenderType"="Opaque"}
LOD 200
// other code...
}Unity内置的Shader使用了不同的LOD值,比如Diffuse的LOD为200,而Bumped Specular的LOD为400。
¶ 8.2 代码方面的优化
在实现游戏效果时,我们可以选择在哪里进行某些特定的运算。通常来讲,游戏需要计算的对象,顶点和像素的数目排序是,对象数 < 顶点数 < 像素数。因此应该尽可能的把计算放在每个对象或者逐顶点上。
编码所涉及到的内容比较庞杂,而且不同的平台上可能存在差异。因而这里给出了相对来说比较比较通用的规则
- 尽可能的使用低精度的浮点数进行计算,并且避免在不同的精度之间进行转换。
- 尽量避免使用全屏幕的PostProces。
- 高精度的运算尽量预先计算好查找表。或者转移到顶点着色器中进行。
- 尽量把多个特效合成到一个Shader当中,比如颜色校正和添加噪声等屏幕效果可以合在一起做。
- 尽量不要使用分支语句和循环语句
- 尽可能的避免类似于sin,tan,pow,log等较为复杂的数学运算。我们可以事先计算好查找表。
- 尽可能的不要使用discard操作,这会影响某些硬件的优化。
¶ 9.小结
虽然内容比较多,但是这些内容都比较玄,因为我们很难直观的把它放到一个具体的情境中去,比如你要开发2D游戏,可能很多内容都不相关,甚至一些相对较小的游戏,你可以不在乎性能优化。但是我们仍然要注意,仍然要时刻保持警惕,在2D或者相对较小的3D游戏当中容错率相对来说还是挺大的,但是在一些相对较大的3D单机作品或者网游当中,性能成为了非常重要的指标,较差的优化可能会让一些配置较差的用户无法流畅的运行游戏,从而导致客户的流失。因而无论什么时候,性能都是我们时刻要注意的内容。
本节没有使用任何着色器代码,几乎都是一些线性知识。